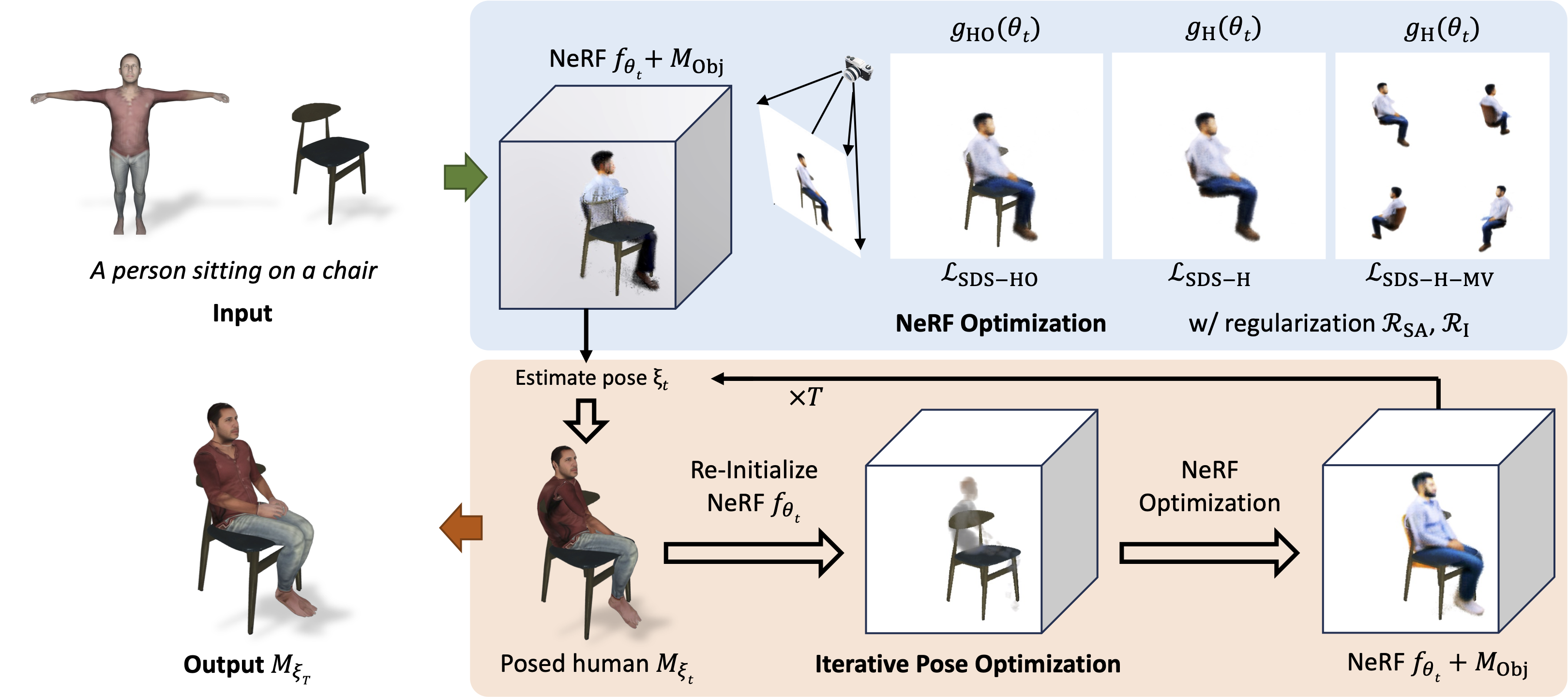
We present DreamHOI, a novel method for zero-shot synthesis of human-object
interactions (HOIs), enabling a 3D human model to realistically interact with any given object based on a
textual description.
This task is complicated by the varying categories and geometries of real-world objects and the scarcity
of datasets encompassing diverse HOIs.
To circumvent the need for extensive data, we leverage text-to-image diffusion models trained on billions
of image-caption pairs.
We optimize the articulation of a skinned human mesh using Score Distillation Sampling (SDS) gradients
obtained from these models, which predict image-space edits.
However, directly backpropagating image-space gradients into complex articulation parameters is
ineffective due to the local nature of such gradients.
To overcome this, we introduce a dual implicit-explicit representation of a skinned mesh, combining
(implicit) neural radiance fields (NeRFs) with (explicit) skeleton-driven mesh articulation.
During optimization, we transition between implicit and explicit forms, grounding the NeRF generation
while refining the mesh articulation.
We validate our approach through extensive experiments, demonstrating its effectiveness in generating
realistic HOIs.